Incident management
Resolve issues faster, keep employees productive, and ensure business continuity while improving IT efficiency.

Less searching, more working
With Freshservice, employees can raise issues on Slack, Microsoft Teams, email, mobile apps, or support portals. Agents track incidents in a single view to speed up responses and resolutions.


Super-efficient staff, systems, and incident solutions
It teams save time with drag-and-drop automations to help them deliver on SLAs. Tickets are auto-assigned to the right agents to speed up workflows. AI assistance summarizes tickets and identifies similar incidents.
Explore IT automation
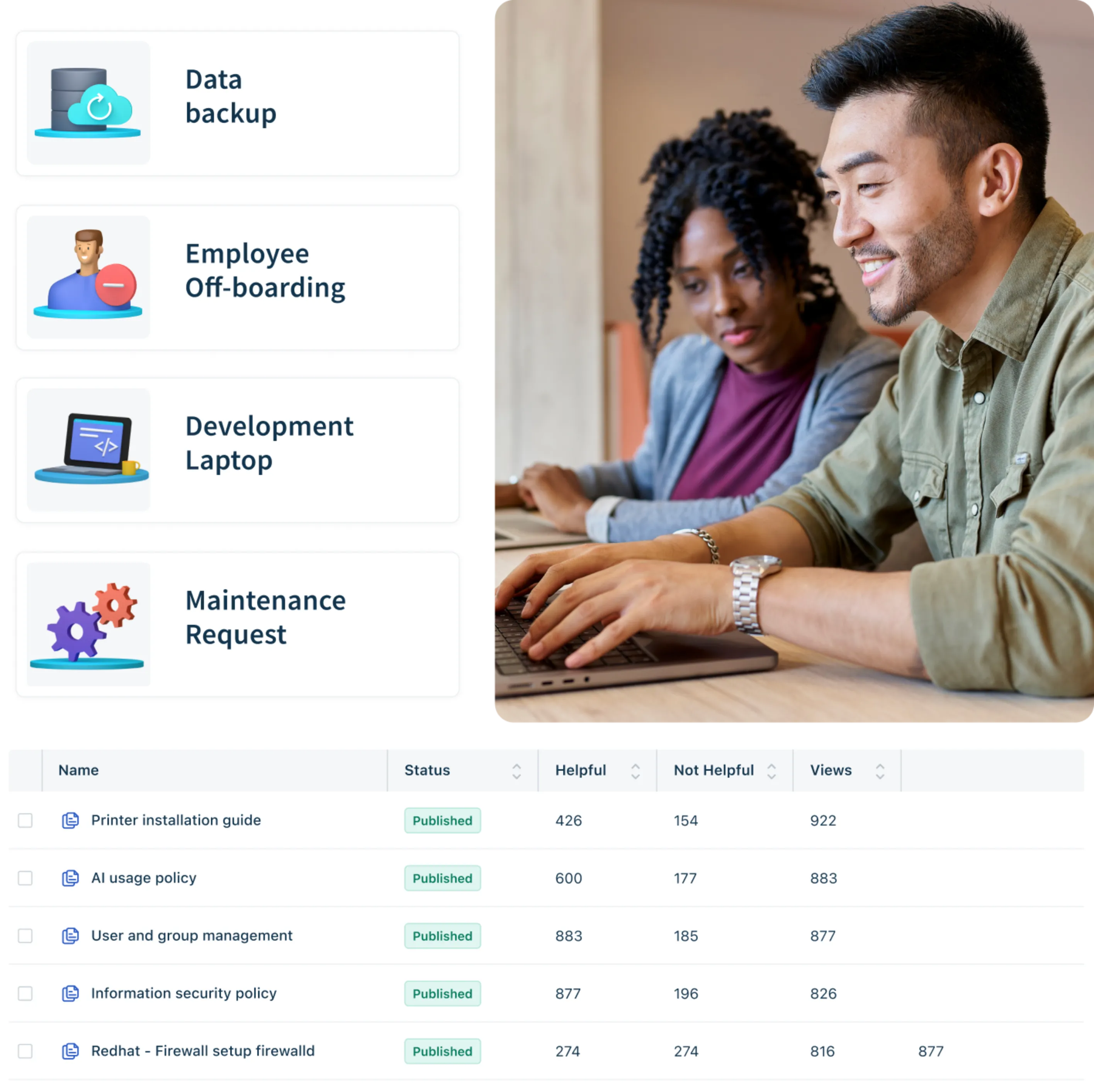
Knowledge is power (and productivity)
Freshservice’s integrated knowledge base expedites self-service; AI assistance helps human agents auto-generate help articles and deflects simple employee queries with short, actionable responses.
Explore our knowledge base
More Freshservice features
Freshservice’s efficient incident management begins with a single view to track, prioritize, and assign tickets—and assemble the right team to resolve quickly.
Multiple SLAs
Teams can create multiple SLA policies to suit task deadlines or enforce a different policy for tickets based on business hours, specific departments, or groups.


Explore capabilities
Automate, streamline, organize, and get more done—faster and easier than ever before.
See what’s newFreddy AI
Deliver self-service for customers, quicker resolutions for agents, and better insights for managers.
Omnichannel
Text, email, tickets, or Teams—Freshservice puts them all together in a single view.
ITSM
Seamless service management, efficiency with AI and automation, and insights for managers.
ITOM
Consolidate, collaborate, and resolve fast with a unified solution, with AI to give you a boost.
ITAM
See it all in real time: hardware, software, and SaaS in an auto-updating CMDB.
IT modernization
Automate and simplify your IT operations, reduce repetitive work, and make data-driven decisions.
Experience intelligent incident management, powered by AI
14 days. No credit card required. No strings attached.