Störungsmanagement? Der vollständige Leitfaden
Ein Überblick über die Grundlagen des Störungsmanagements

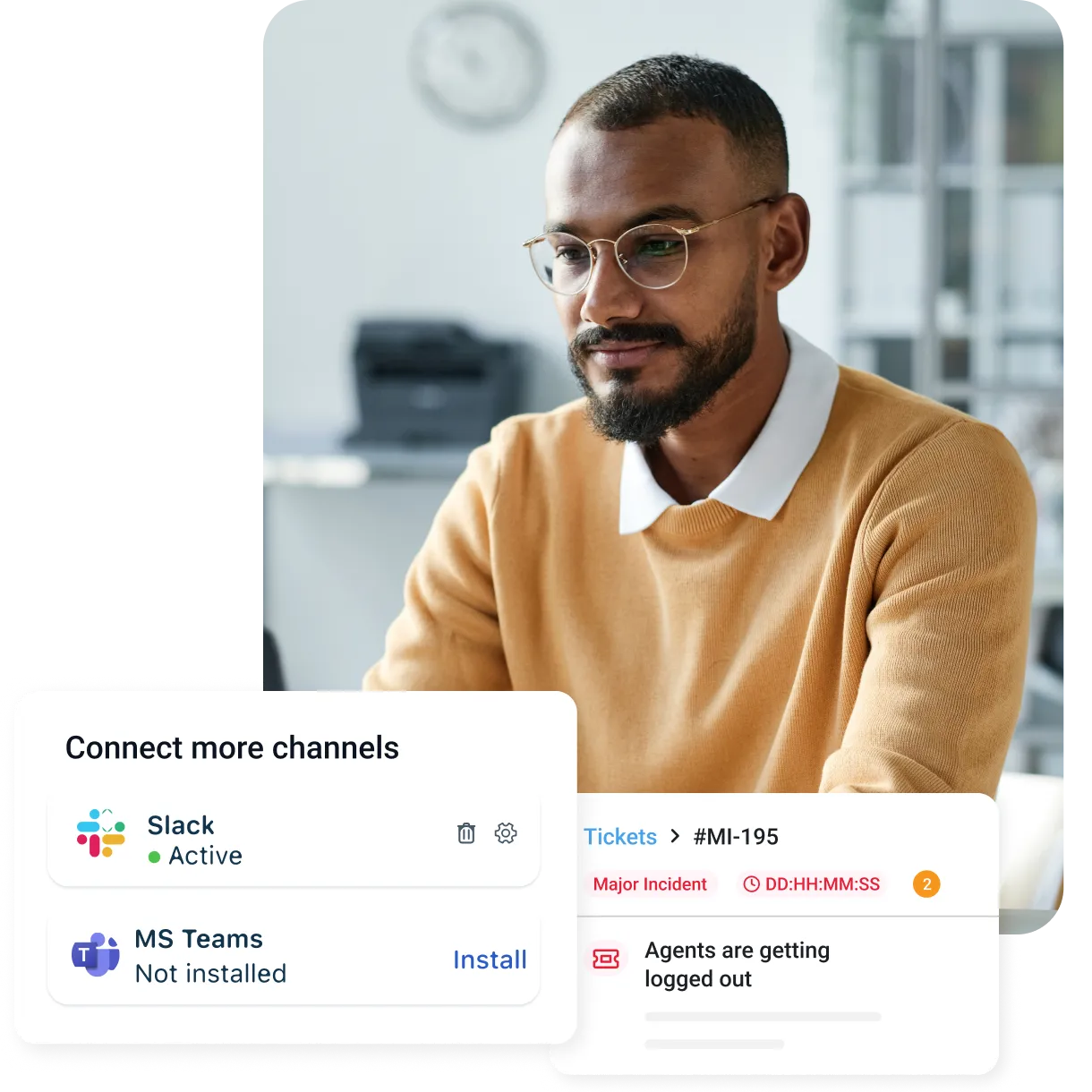
TL;DR
Here's a summary of the page:
IT incident management provides structured processes for identifying, logging, and resolving unplanned IT disruptions like outages, bugs, and security breaches to minimize business impact.
Effective systems reduce downtime costs (up to $9,000 per minute), improve response times through automation, real-time alerts, and structured workflows.
Leading solutions like Freshservice offer AI-driven prioritization, automated escalation, knowledge base integration, and SLA tracking for faster resolution.
Key features to implement include clear incident classification, automation tools, response playbooks, team training, and metrics tracking for continuous improvement.
Read the full guide to learn how structured incident management can transform your IT operations and response capabilities.
May 19, 202515 MIN READ
Every minute of IT downtime can cost your business up to $9,0001, not to mention lost trust, productivity, and revenue. Picture your e-commerce platform crashing during peak hours. Orders are stalling, customers are churning, and revenue is plummeting.
The longer it takes to respond, the bigger the damage. This is where a well-structured IT incident management system acts as a game changer. In addition to reducing downtime, the IT incident management system helps implement effective processes with smart strategies. Let's understand how it drives efficiency and fast-tracks issue resolution.
Was ist Störungsmanagement?
Das Störungsmanagement ist ein wichtiger Aspekt des IT-Service-Managements (ITSM). Es geht darum, einen gestörten Dienst nach einem Vorfall so schnell wie möglich wieder in den Normalzustand zu versetzen, die Auswirkungen auf den Geschäftsbetrieb zu minimieren und sicherzustellen, dass das bestmögliche Niveau an Service und Verfügbarkeit aufrechterhalten wird. Es umfasst eine Reihe von Praktiken zur Ermittlung, Analyse und Lösung betrieblicher Probleme und bringt eine Vielzahl von Vorteilen mit sich.
Durch die Implementierung eines robusten Prozesses für das Störungsmanagement können Unternehmen ihre Fähigkeit verbessern, auf Vorfälle zu reagieren und zukünftige Störungen zu verhindern. Dieser proaktive Ansatz ermöglicht es Unternehmen, potenzielle Probleme zu erkennen und zu beheben, bevor sie eskalieren, wodurch die Auswirkungen auf den Betrieb minimiert werden. Insgesamt spielt das Störfallmanagement eine wichtige Rolle bei der Aufrechterhaltung der Stabilität und Zuverlässigkeit von IT-Diensten und ermöglicht es Unternehmen, ihren Kunden qualitativ hochwertige Dienste anzubieten.
Was ist IT-Störungsmanagement?
Das IT-Störungsmanagementist ein wichtiger Prozess, der von verschiedenen Einrichtungen wie IT-Dienstleistern, IT-Abteilungen von Unternehmen und Managed Service Providern (MSPs) genutzt wird, um Vorfälle, die sich auf ihre IT-Dienste auswirken, effektiv zu bearbeiten und zu lösen.
Diese Praxis ist für alle Organisationen von Bedeutung, einschließlich Regierungsbehörden, Finanzinstituten, Gesundheitsdienstleistern und Bildungseinrichtungen, da sie in hohem Maße von ihrer IT-Infrastruktur abhängig sind, um ihre Geschäftsprozesse zu unterstützen und zu rationalisieren. Durch die Einführung eines IT-Störungsmanagements können diese Unternehmen das reibungslose Funktionieren ihrer IT-Dienste sicherstellen und Unterbrechungen auf ein Minimum reduzieren.
Die Bedeutung des Störungsmanagements
Das Störungsmanagement spielt eine entscheidende Rolle für den reibungslosen Betrieb eines jeden Unternehmens, was sich letztlich auf alles auswirkt, von der Kundenzufriedenheit über die Zufriedenheit der Mitarbeiter bis hin zu den Verkaufszahlen und mehr. Serviceunterbrechungen können unmittelbar mit Umsatzeinbußen verbunden sein, und je nachdem, wie sehr die lebenswichtigen Abläufe oder Produkte eines Unternehmens von Hardware oder Software abhängen, können diese Unterbrechungen zu Gewinneinbußen und zum Verlust von Arbeitsplätzen führen, da sie die Kundenzufriedenheit und das Vertrauen beeinträchtigen.
Einer der Hauptgründe, warum das Störungsmanagement wichtig ist, liegt darin, dass es Unternehmen hilft, umgehend auf Störungen zu reagieren. Wenn es zu einem Zwischenfall kommt, ist ein strukturierter Ansatz erforderlich, um schnell und effizient reagieren zu können. Mit einem gut definierten Prozess für das Störungsmanagement können Unternehmen sicherstellen, dass Störungen erkannt, bewertet und umgehend behoben werden.
Darüber hinaus hilft das Störungsmanagement den Unternehmen, die Ursachen von Störungen zu ermitteln. Unternehmen können durch eine gründliche Untersuchung von Störungen Einblicke in die zugrunde liegenden Probleme gewinnen, die zu der Störung geführt haben. Diese Informationen können dann zur Durchführung von Präventivmaßnahmen und zur Verbesserung der allgemeinen Stabilität und Zuverlässigkeit des Systems oder Netzes genutzt werden.
What are the common types of IT incidents?
Not all IT disruptions are the same. Some can bring operations to a standstill, while others quietly impact performance over time. Understanding the most common types of incidents helps teams plan better responses and allocate resources where they’re needed most.
Here are five types of IT incidents you’ll encounter frequently:


Hardware failures Issues like hard drive crashes, power supply problems, or overheating servers can immediately take systems offline. Quick detection and replacement are essential to avoid extended downtime.
Software bugs Problems in code, often introduced during updates or deployments, can cause apps to crash, slow down, or behave unexpectedly. These incidents need fast triage and a reliable rollback plan.
Network outages Connectivity issues from firewall misconfigurations, ISP failures, or bandwidth overloads can interrupt access to business-critical tools. Resolving them often requires coordination between IT teams and external vendors.
Security breaches Incidents like phishing, malware, or unauthorized access attempts are high-priority. They require fast containment, detailed investigation, and follow-up action to protect data and restore trust.
Human errors Mistakes like misconfigurations, accidental deletions, or missed updates are common causes of disruption. Strong change management policies can help reduce how often they happen.
Identifying these incident types early helps IT teams respond faster and keep disruptions to a minimum.
IT incident management process (Step by step)
The impact of an IT issue, whether minor or major, depends on the strength and structure of your incident management process. A reactive approach often leads to delays and confusion. But with a clear, step-by-step process, you reduce downtime and keep operations running smoothly.
Let’s understand the six critical components of an effective IT incident management system:
1. Incident identification and logging
You need to detect the issue early. Proactive monitoring minimizes damage and enables faster response.
Utilize real-time monitoring tools to identify anomalies and trigger alerts promptly as issues arise.
Enable incident reporting from employees, and don’t assume “someone else” will flag it.
Document incidents thoroughly, including:
Time of occurrence
Affected systems/users
Error messages/logs
Initial actions taken
2. Categorization and prioritization
Not all incidents carry the same level of significance. Some halt critical services, while others are minor hiccups. Effective categorization and prioritization ensure that urgent issues are addressed first, minimizing their impact and preventing escalation.
Categorization: Group incidents by type, impact area, or affected systems to route them effectively.
Category | Example incidents | Business impact |
Security | Unauthorized access, phishing attempts, DDoS attacks | Data loss, financial implications, compliance violations |
Network issues | Network outages, latency issues, firewall errors | Reduced productivity, delayed operations |
Application failures | CRM crashes, ERP failures | Workflow interruptions, lower customer satisfaction |
Hardware failures | Hard drive failures, server crashes, overheating components | Downtime, data recovery costs, hardware replacement |
User support requests | Login issues, password resets, new user access | Low-impact but high-frequency tickets |
Prioritization: After categorizing, determine which incidents require urgent attention based on business impact and time sensitivity.
Tools like the Impact-Urgency Matrix help teams prioritize tasks effectively. For instance, a payment system outage affecting customers is high-impact and urgent. In contrast, a small UI issue in an internal dashboard can be deferred.
Another key framework is SLA management. SLAs define the timeframe for resolving incidents. For example, a checkout failure in an e-commerce system may have a 30-minute resolution SLA to prevent revenue loss. Lower-priority issues, such as delayed analytics reports, often have relaxed Service Level Agreements (SLAs).
The goal is straightforward: Prioritize incidents effectively so that teams resolve the right issues at the right time with minimal delay.
3. Investigation and diagnosis
After logging and prioritizing incidents, the next step is to identify the root cause using proven techniques.
The 5 whys method
Ask “why” repeatedly, typically five times, to uncover the root cause. For example, if a server keeps crashing:
Why? Is it because of high CPU usage?
Why? Did a recent software update increase resource demand?
Why? Was the update not tested for scalability?
Why? Could the lack of a structured testing process be the reason?
Why? Could the absence of clear change management policies be the cause?
Root cause: Lack of structured testing and change management.
Simulate and replicate the issue
Recreating the issue in a test environment helps isolate the cause. For instance, if a payment fails, simulating the transaction under different conditions can help determine whether it's a browser error, API failure, or backend bug.
4. Resolution and recovery
This is the stage where teams implement fixes and restore services.
Apply fixes (patches, config updates, scripts)
Test thoroughly in a staging or sandbox environment
Deploy to affected systems
Validate the fix with monitoring and checks
Watch for regressions or new issues
This stage helps teams not only resolve issues but also ensure the fix is effective and won't create new problems.
5. Post-incident review and learning
Resolving an issue isn’t the end. Teams must conduct a thorough post-incident review to:
Identify underlying root causes and recurring patterns
Update internal documentation and knowledge base
Implement changes to prevent similar incidents
Sehen Sie, wie 89 % der Unternehmen generative KI zu ihrem Wachstumsmotor machen
What are the key benefits of an effective IT incident management system?
An effective IT incident management system provides a structured approach to handling IT disruptions and ensures smoother operations through:
Reduced downtime: Minimizes business interruptions by swiftly addressing and resolving incidents
Improved user satisfaction: Enhances user confidence and productivity through timely and effective support
Faster resolution time: Uses defined processes and knowledge sharing to expedite incident resolution
Better resource allocation: Provides data-driven insights for optimizing IT support staffing and resource deployment
Enhanced service quality: Contributes to a more stable and reliable IT environment, improving overall service delivery
Wo investieren intelligente CIOs im Jahr 2025? Erhalten Sie Einblicke in die 5 wichtigsten IT-Prioritäten
How IT incident management improves response time
When incidents occur, response time is critical. Faster detection and resolution mean less business impact, but what actually improves response time in practice? Let's find out.
1. Structured process flow: standardizing incident response from start to finish
Disorganized responses cause delays. A well-defined incident management system provides consistency, clarity, and faster resolution. IT incident management ensures a structured response workflow that guides teams through every step.
Standardized workflows guide every incident through consistent resolution steps
Predefined categories ensure accurate routing, avoiding delays
Automation and playbooks provide teams with clear, repeatable actions
A structured approach to IT incident management ensures that no time is wasted on unclear responsibilities or inefficient troubleshooting.
2. Real-time alerts: minimize detection delays with automation
Response delays often start with detection delays. Real-time monitoring tools integrated with your IT incident management system help teams respond instantly.
Immediate multi-channel alerts (email, chat, SMS) with workflow automation ensure teams are notified instantly.
IT alert management filters out noise, so only critical incidents trigger responses.
Predictive monitoring detects issues before they escalate.
IT incident management reduces the critical time gap between failure and response by alerting teams the moment an incident occurs.
3. Escalation workflows: route issues to the right team instantly
Without defined escalation paths, teams waste time determining ownership and accountability. The IT incident management system should automate this routing.
Set clear severity levels (P1–P3) to prioritize critical issues
Automate routing based on issue type—network, app, or security
Enforce SLAs to hold teams accountable for timely responses
Structured incident management reduces delays and accelerates resolution by clarifying ownership and escalation processes.
4. Knowledge base integration: reuse past solutions to resolve issues faster
IT teams often waste time solving the same problems repeatedly, especially when past solutions aren’t documented or accessible. Each resolved incident holds valuable insights that can inform and accelerate future responses. An integrated knowledge management system enables this.
Documented fixes are searchable and accessible
AI-powered suggestions provide relevant solutions instantly
Teams can resolve recurring issues faster by referencing past tickets
IT incident management helps resolve common issues faster by transforming past incidents into actionable knowledge.
5. Real-time collaboration: eliminate silos to resolve faster
Major incidents often involve multiple teams, such as network, security, and development. Without a central platform, collaboration breaks down.
Centralized incident dashboards consolidate scattered communication and provide better incident response.
Everyone sees real-time status, reducing duplicate work
Task assignments clarify ownership and prevent delays
Real-time collaboration through incident management helps eliminate delays caused by fragmented communication.
6. SLA tracking: stay compliant and resolve incidents on time
Response speed isn’t enough; teams also need to meet predefined SLAs. A modern incident management system enforces this automatically.
Automated tracking ensures SLA deadlines are never missed
Escalations alert managers before breaches occur
Priority-based SLAs differentiate critical from routine issues
SLA management helps teams stay on track with response times, leading to more consistent and predictable resolutions.
7. Reporting and analytics: improve incident response with real-time insights
To improve incident response, teams must analyze where delays happen and why. Reporting tools in Freshservice enable this visibility.
Dashboards show live incident statuses across teams
Key metrics like MTTR, FCR, and SLA compliance highlight gaps
Historical trends reveal recurring problems and areas for automation
Analytics help teams identify inefficiencies and improve response times throughout the incident lifecycle.
Looking for reliable IT incident management software? Freshservice offers a unified platform that streamlines workflows, automates alerts, and reduces resolution times. Take a product tour to see it in action.
Most organizations adopt an ITIL-based IT incident management system to bring structure, compliance, and accountability to their response process. Tools like Freshservice follow ITIL best practices and offer built-in automation, SLA tracking, and knowledge integration to support seamless issue resolution.
Störfallmanagement Best Practices
Die Implementierung von ITIL Best Practices für das Störungsmanagement beinhaltet einen strukturierten Ansatz zur Behandlung von Störzngen, um die Auswirkungen auf den Geschäftsbetrieb zu minimieren. Hier sind auch dafür einige Best Practices.
Abschluss des Vorfalls: Sobald eine Störung behoben ist, vergewissern Sie sich beim Benutzer, dass der Dienst wiederhergestellt ist und dass er zufrieden ist, bevor Sie die Störung formell abschließen.
Kommunikation: Halten Sie Benutzer und Interessengruppen während des gesamten Lebenszyklus einer Störung auf dem Laufenden, insbesondere bei größeren Vorfällen mit weitreichenden Auswirkungen.
Überprüfung von Störungen und kontinuierliche Verbesserung: Überprüfungen nach einer Störung helfen zu verstehen, was falsch gelaufen ist, was richtig gemacht wurde und wie ähnliche Störungen in Zukunft verhindert oder besser bewältigt werden können.
Schulung und Sensibilisierung: Durch regelmäßige Schulungen wird sichergestellt, dass das Störungsmanagementteam die Prozesse, Tools und bewährten Verfahren kennt.
Tool-Nutzung: Verwenden Sie ein IT-Service-Management-Tool (ITSM), das mit den ITIL-Praktiken übereinstimmt, um den Lebenszyklus von Störungen systematisch zu verwalten.
Integration mit anderen Prozessen: Stellen Sie sicher, dass das Störungsmanagement gut mit anderen ITIL-Prozessen wie Problemmanagement, Änderungsmanagement und Konfigurationsmanagement integriert ist, um einen ganzheitlichen Ansatz zu gewährleisten.
Leistungsmessung: Verwenden Sie Key Performance Indicators (KPIs), um die Effizienz und Effektivität des Störfallmanagements zu messen und Verbesserungen voranzutreiben.
Service Level Agreements (SLAs): Definieren Sie SLAs und halten Sie diese ein, um klare Erwartungen für die Reaktions- und Lösungszeiten bei Störungen festzulegen.
Durch die Einhaltung dieser Best Practices können Unternehmen einen konsistenten und effektiven Ansatz für das Störfallsmanagement sicherstellen und so Ausfallzeiten reduzieren und ein hohes Maß an Servicequalität und Kundenzufriedenheit aufrechterhalten.
Optimieren Sie Ihren Aufbau des Störungsmanagements
Um das Störungsmanagement effektiv zu optimieren, sollten Unternehmen den Einsatz moderner ITSM-Tools in Erwägung ziehen, die ihre betriebliche Effizienz steigern können. Durch die Automatisierung bestimmter Prozesse, wie z. B. die Erstellung von Tickets und die Behebung von Störungen, können Unternehmen die Reaktionszeiten erheblich verkürzen und das Störungsmanagement insgesamt verbessern.
Darüber hinaus ist es für Unternehmen von entscheidender Bedeutung, die kontinuierliche Aus- und Weiterbildung ihrer Mitarbeiter zu fördern und sicherzustellen, dass diese mit den neuesten Verfahren und technologischen Fortschritten vertraut sind. Auf diese Weise sind sie in der Lage, Störungen effektiv zu bearbeiten und zeitnahe Lösungen zu liefern, was letztlich den gesamten Prozess des Störungsmanagements verbessert.
Die Wahl des richtigen Tools für das Störungsmanagement
Bei der Auswahl des richtigen Störungsmanagement-Tools für Ihr Unternehmen sollten Sie folgende Schlüsselfaktoren berücksichtigen:
1. Zugänglichkeit und Benutzerfreundlichkeit: Wählen Sie eine intuitive Software für IT- und Nicht-IT-Benutzer, die Self-Service-Optionen und Multikanal-Support für das Einreichen von Tickets bietet.
2. Automatisierungsmöglichkeiten: Wählen Sie eine Lösung, die Routineaufgaben wie die Weiterleitung und Priorisierung von Tickets automatisiert. Dies trägt dazu bei, die Effizienz zu steigern und die Zeit des IT-Teams für gezieltere Aktivitäten freizugeben.
3. Einheitliches Dashboard: Stellen Sie sicher, dass das Tool über ein zentrales Dashboard zur Verfolgung von Störungen, zur Erleichterung der Zusammenarbeit und zur Leistungsüberwachung verfügt.
4. Warnungen und Benachrichtigungen in Echtzeit: Wählen Sie Tools mit Echtzeit-Updates, um die Benutzer über den Fortschritt der Störung auf dem Laufenden zu halten und schnelle Reaktionen zu ermöglichen.
5. Umfassende Wissensdatenbank: Entscheiden Sie sich für Tools mit einer umfassenden Wissensdatenbank, um die Nutzer mit Self-Service-Optionen zu unterstützen und das Volumen der eingehenden Tickets zu reduzieren. Integrationsfähigkeit: Die Software sollte sich problemlos in andere Systeme und Anwendungen integrieren lassen, die in Ihrem Unternehmen verwendet werden, wie z. B. Bereitschaftsdienstmanagement oder ITSM.
Mobile Kompatibilität: Stellen Sie sicher, dass Tools mit mobilen Geräten kompatibel sind, damit die Benutzer den Ticketverlauf verfolgen und aus der Ferne auf das System zugreifen können.
How do you choose the right IT incident management tool?
Selecting the right IT incident management tool is vital. Key features to consider include user-friendliness, automation capabilities, reporting dashboards, and integration options. Organizations must also decide between cloud-based solutions, offering scalability and accessibility, and on-premise solutions, providing greater control over data. The choice depends on specific business needs and infrastructure requirements.
Best ways to implement IT incident management with Freshservice
Freshservice offers an intuitive, automation-first ITSM platform designed to streamline IT security incident management across departments and geographies. It helps ensure consistent resolution for security-related disruptions.
However, tools alone won’t reduce response times. You need the right implementation strategy.
Here are the top incident management best practices for efficient issue resolution.
1. Establishing clear incident classification
Understanding the impact and urgency of an incident is the first step toward resolving it quickly. Use a prioritization matrix to guide the process.
Impact: How many users/systems are affected?
Urgency: How quickly does it need to be fixed?
However, first, accurately classify each incident, as this ensures proper routing and resolution. A clear classification system ensures that each incident is routed to the right team and handled appropriately.
Here’s a table that categorizes common incident types:
Category | Examples | Priority level | Responsible team |
IT security incident | Unauthorized access, phishing attack | P1 | Security operations |
Network issue | Server outage, slow internet | P1 - P2 | Network team |
Hardware failure | Crashed laptop, broken printer | P2 - P3 | IT support |
Software bug | Application crash, system error | P2 - P3 | Development team |
User access issues | New employee login, password reset | P3 - P4 | IT helpdesk |
Performance degradation | Slow application response, intermittent failures | P2 - P3 | Application support |
Non-urgent user query | How-to questions, non-urgent troubleshooting | P4 - P5 | IT support/helpdesk |
Sample incident prioritization matrix:
Impact/urgency | High urgency (Immediate impact) | Medium urgency (Needs resolution soon) | Low urgency (Minimal disruption) |
High impact (Business-critical, affects all users or core services) | Priority 1: Complete server outage affecting all customers | Priority 2: Severe performance issues in a core system (e.g., checkout, CRM) | Priority 3: Intermittent failures in widely used business tools |
Medium impact (Affects a specific team or department) | Priority 2: Business application unavailable for a key department | Priority 3: Functional bug impacting reporting or dashboard accuracy | Priority 4: Software update request with minimal operational impact |
Low impact (Affects one or a few users; workaround available) | Priority 3: Single user unable to access a tool | Priority 4: UI issue in a non-critical system | Priority 5: Minor enhancement or low-urgency feature request |
2. Design SLA-based escalation procedures
Instead of relying on manual escalation, use Freshservice to escalate incidents based on SLA rules automatically. Escalation managers can then monitor SLAs, ensure compliance, oversee major incident management, and prevent bottlenecks from occurring.
3. Build and automate response playbooks
Response playbooks standardize recurring fixes, reduce manual work, and enable faster resolutions.
Use templates for recurring issues like password resets or VPN access failures
Set up automation to auto-assign incidents, like routing network issues directly to the IT helpdesk
4. Train teams for real-world incident scenarios
Train your IT team in structured troubleshooting, effective communication, and real-time collaboration. Conduct mock incident drills regularly to test response times and enhance readiness.
5. Use metrics to drive continuous improvement
To improve response time, track the right KPIs:
Mean Time to Acknowledge (MTTA): Speed of initial response
Mean time to Resolution (MTTR): Time to final resolution
First Call Resolution (FCR) rate: Resolved on first contact
Real results: How Freshservice improved response times for global teams
Here’s how leading organizations used Freshservice to improve incident response:
Carrefour Belgium boosted efficiency across 15 help desks
Carrefour Belgium utilized Freshservice to unify help desks, automate workflows, and resolve issues more efficiently across 350+ agents. With improved service catalogs and vendor integrations, support efficiency and user satisfaction increased significantly.
Before Freshservice | After Freshservice |
15 disconnected helpdesks | Unified system with eight integrated helpdesks (more in progress) |
Scattered tools, manual processes for incident management | A centralized self-service portal for streamlined reporting and tracking |
Outdated, fragmented processes | Automation-powered, standardized workflows |
Slow due to lack of integration | Faster resolution with clear escalation paths |
Low agent productivity due to inefficient processes | Over 350 agents empowered with modern tools |
Rigid legacy system | Cloud-based solution with future-ready scalability |
"Our Freshservice implementation has really been a success story. It allows us to delight users with a single, unified experience."
How HelloFresh optimized incident management
HelloFresh utilized Freshservice for centralized logging, faster resolution, and smoother team collaboration.
Before Freshservice | After Freshservice |
Manual incident reporting via email and chat, causing delays | Centralized service desk with automated ticketing |
No unified system, difficult to track issues | Clear incident logs and real-time monitoring |
Slow response time due to a lack of prioritization | Faster resolution with automated workflows |
IT team overwhelmed with repetitive tasks | Reduced workload through automation and self-service |
Frustration due to slow employee support | Improved satisfaction with quicker resolutions |
"We have found great value in Freshservice’s configurable workflows, unified portal, and the ability to set up the platform in local languages. We believe this will help the way we manage incidents across our locations to provide the best experience for our customers."
How can Freshservice help future-proof your incident management process?
The strength of your incident management process is measured by how quickly you can restore services and minimize disruption. With Freshservice, you gain automation, AI-driven insights, and structured workflows that enable you to respond faster, reduce downtime, and keep your teams productive.
Don’t let slow, manual processes hold you back. Sign up for Freshservice today to discover how it can enhance your incident response times and overall service delivery.
Entsprechen Ihre IT-Prioritäten denen globaler Marktführer? Entdecken Sie die wichtigsten CIO-Investitionstrends für 2025
Weiterführende Materialien
Ihr ITSM-Guide – klar und auf den Punkt gebracht
Umfassender Leitfaden zu ITOM
Effizientere Abläufe durch Automatisierungen und KI
Frequently asked questions
What’s the difference between IT incident management and problem management?
IT incident management focuses on restoring services quickly after a disruption. On the other hand, problem management seeks to identify the root cause and helps prevent the issue from recurring.
How long does it take to implement an IT incident management system?
With the right tools, such as Freshservice, most organizations can establish an IT incident management system within a few weeks.
Which metrics measure the effectiveness of an incident management strategy?
Key metrics that measure the effectiveness of an incident management strategy include Mean Time to Resolution (MTTR), First Call Resolution rate (FCR), Service Level Agreement (SLA) compliance, and user satisfaction scores.
How does automation improve IT incident response time?
Automation helps route tickets, assign priorities, escalate issues, and apply fixes faster. This reduces delays and avoids manual errors.
How does Freshservice align with ITIL-based incident management?
Freshservice adheres to ITIL principles by providing structured workflows, SLA tracking, automated escalation, and knowledge management features.
What is an example of an IT incident?
A server outage that stops online transactions during peak hours is a typical IT incident. It requires a prompt response to prevent revenue loss and minimize customer impact.