Best AIOps platforms for proactive IT management in 2025
Freshservice simplifies IT operations with clear tools and processes, helping your team deliver fast, reliable, and predictable service every time.

Jun 05, 202517 MIN READ
Modern IT environments generate thousands of alerts daily, many of which are false positives. With leaner teams and complex systems, managing this noise efficiently is critical. AIOps helps streamline operations by filtering alerts, prioritizing incidents, and improving response times through automation.
AIOps tools use intelligent automation to filter noise, detect issues early, and even resolve them before users notice. In 2025, they’re faster, sharper, and more business-aware than ever. This guide covers the 15 best AIOps tools right now, rated for how well they cut through complexity and deliver real, usable insights when it matters most.
What are AIOps tools?
AIOps (Artificial Intelligence for IT Operations) tools use machine learning, big data, and automation to streamline and improve IT operations. Instead of relying on manual monitoring, they analyze logs, metrics, and events in real time to detect issues, prevent outages, and resolve problems faster.
Unlike traditional monitoring tools, AIOps platforms don’t just alert you, they predict incidents, offer root cause insights, and even trigger automated fixes. It’s not just smarter IT, it’s proactive, self-healing, and built for scale.


What AIOps tools actually do (when they work well)
When used right, the best AIOps platforms can lead to fewer late-night emergencies, quicker fixes, and more time for your team to focus on real work. The best tools don’t just tell you what broke; they connect the dots, show you what needs attention, and often fix things automatically.
From surfacing the root cause of a cascading failure to preventing incidents with early signals, AIOps tools step in quietly, handle the grunt work, and help your team stay ahead of the curve. In this list, we’ve focused on tools that actually deliver on that promise.
Top AIOps tools comparison at a glance
Take a look at the top AIOps tools here:
Tool | Starting price | Implementation complexity | Core AIOps capabilities | GenAI support | Key integrations | Best for |
Freshservice | $19/agent/month | Low | Alert correlation, RCA, autonomous remediation, and predictive analytics | Yes, Freddy AI and GenAI Ops (auto summarization, RCA, and article generation) | Microsoft Teams, SecPod, Slack, TeamViewer, Jira, and Azure AD | Mid-size to enterprise IT teams needing fast, no-code AIOps + ITSM |
Datadog | $15/month/host | Medium | Unified observability, RCA, AI-based forecasting, and event correlation | Yes – ML-powered anomaly detection, and alert tuning | AWS, Azure, Kubernetes, Oracle, and Google Cloud | Mid-to-large teams managing dynamic cloud infrastructure |
AppDynamics | Evolved pricing | Medium-High | Application performance monitoring, KPI mapping, and root cause correlation | Moderate – Basic anomaly detection, and AI-assisted baselining | Jira, ServiceNow, Splunk, Rookout, DB CAM, CompuwareStrobe | Enterprises already using Cisco or requiring deep application insights |
BigPanda | Quote-based | Medium | Event correlation, incident intelligence, and automated workflows | Limited – AI-powered root cause analysis, impact estimation, and reasoning | AppDynamics, Datadog, Splunk, Jira, Amazon CloudTrail, Slack, and Asana | Large enterprises focused on reducing alert fatigue and downtime |
PagerDuty | $699/month | Medium | Real-time incident response, alert deduplication, and orchestration | Limited – Basic AI for alert suppression and escalation | AWS, Salesforce, Atlassian, Zendesk, Datadog, and ServiceNow | DevOps-centric orgs prioritizing rapid response and reliability |
Dynatrace | Usage-based | High | Full-stack observability, RCA, auto-discovery, and AI-driven analytics | Yes – Davis AI (causal analysis and predictive insights) | Jira, Slack, AWS, Azure, and Google Cloud | Enterprises needing proactive cloud-native AIOps and automation |
Moogsoft | Quote-based | Medium | Alert correlation, RCA, incident triage, predictive analytics, and ML-based classification | Limited – Some ML for clustering, lacks detailed GenAI | AWS, Slack, AppDynamics, New Relic, PagerDuty, and XMatters | IT teams in complex, hybrid environments needing situational awareness |
LogicMonitor | $22/resource/month | Medium | Hybrid infra monitoring, anomaly detection, service health scoring | Yes – Edwin AI (GenAI UI, incident recommendations) | Azure, Kubernetes, AWS, Cisco, IBM AIX, Twilio, Zoom, MS365 | MSPs and large orgs needing scalable GenAI-backed infra visibility |
Splunk ITSI | Quote-based | High | Service-level monitoring, RCA, KPI correlation, and business impact analysis | Yes – AI assistant for RCA and Agentic AI frameworks | Nagios, Solarwinds, Microsoft SCOM, Cloudtrail, and AppDynamics | Enterprises needing full-service intelligence with KPI alignment |
IBM Cloud Pak AIOps | Quote-based | High | Cross-domain ingestion, RCA, dynamic topology, and event compression | Yes – Custom ML (unsupervised training, model management tools available) and GenAI (ChatGPTintegration) | AWS, Azure, Datadog, Dynatrace, GitHub, Google Cloud, IBM Cloud, Instana, and Jira | Large orgs needing deep automation and hybrid data handling |
ServiceNow ITOM | Quote-based | High | IT event management, CMDB discovery, anomaly detection, health log analysis | Yes – Now Assist (GenAI for insights, smart routing, task automation) | Azure, AWS, Cisco, VMware, and GCP | IT ops teams managing hybrid infra with high integration needs |
New Relic | Free+quote-based | Medium | Observability, NRQL queries, causal engine, forecasting | Yes – Causal AI + NRQL (custom forecasting, and root cause mapping) | AWS, Azure, Kubernetes,Slack, and Jenkins | SaaS engineering teams needing fast issue triage with custom metrics |
ScienceLogic SL 1 | $5/device/month | Medium | Infra monitoring, config change tracking, RCA, and automation | Yes – Skylar AI for proactive guidance, real-time data visualization and exploration, and automated troubleshooting | ServiceNow, AWS, Cisco, and Microsoft SCOM | Enterprises with hybrid/multi-cloud infra needing deep visibility |
Zluri | Quote-based | Low | SaaS discovery, access control, shadow IT detection, and cost optimization | Limited – Basic automation, lacks GenAI AIOps depth | Google Workspace, Okta, MS365, and Salesforce | Mid-sized orgs optimizing SaaS usage and internal compliance |
Fabrix.ai | Quote-based | Medium | Noise reduction, predictive incident response, and RDAF orchestration | Yes – Built-in GenAI for dependency mapping, and action suggestions | AppDynamics, ServiceNow, Datadog, and New Relic | Data-heavy enterprises looking for low-code automation + deep insights |
Move beyond break-fix IT. Discover how AI transforms ITSM into a strategic value driver
15 best AIOps tools in 2025
Here's a detailed rundown on the top AIOps tools so you can pick the one that suits you best.
Freshservice

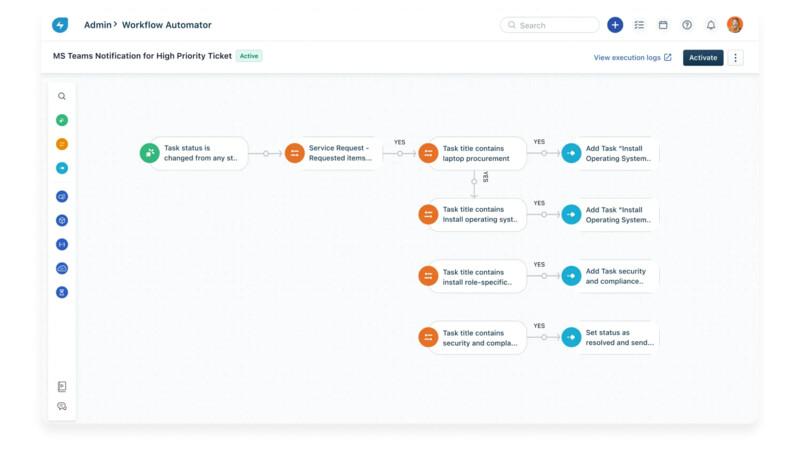
Freshservice is built for the modern IT team that wants speed without sacrificing control. It’s not just an ITOM tool with some AI sprinkled on top. It’s a fully AI-native platform that helps teams move from reactive firefighting to proactive, intelligent operations. From automated incident resolution to GenAI-powered ticket management, Freshservice brings together smart workflows and a user-friendly interface that makes IT ops hassle-free.
Freshservice GenAI intelligently automates IT support workflows, enhancing agent efficiency and user experience. With GenAI applications, you can:

Summarize and categorize incoming incidents
Get AI-driven recommendations for root cause analysis
Generate and improve knowledge articles in no time
Navigate easily using conversational interfaces
Pros
Provides an intuitive user interface with a minimal learning curve
Offers seamless integration with existing business tools and third-party platforms
Enables seamless configuration of the system and gets it up and running in no time
Boasts strong automation capabilities to minimize manual intervention and errors
Provides prompt support and active community resources
Cons
Initial setup may take some time, particularly for teams new to ITSM or AIOps but the flexibility it offers can be well worth the effort.
Advanced reporting requires some customization to unlock its full value, giving teams the ability to shape analytics around their specific goals.
Success metrics
Freshservice delivers measurable impact:
Increased first contact resolution time by 92% while handling a 60% spike in tickets per agent for OdontoCompany (healthcare and pharma)
Achieved a 23% self-service deflection rate with a 96% customer satisfaction score" for Databricks (higher education)
Cut resolution time by 50% with 100% core workflow automation for TaylorMade (retail)


Datadog
Datadog is a cloud-native observability platform built to give you deep visibility into everything, from servers and databases to applications and services.
With powerful AIOps capabilities baked in, it helps teams stay ahead of outages, prioritize what matters, and cut through the noise with smart alerting and predictive insights.
Pros
Offers a consolidated view of efficient incident management
Deduplicates and prioritizes alerts automatically
Has predictive analytics that help you prevent problems before they start
Boasts centralized log management and correlation for faster root cause analysis
Integrates smoothly with tools like AWS, Azure, and Kubernetes
Cons
Alert fatigue needs fine-tuning to avoid overload
Log management is decent, but not the most advanced in the market
Splunk AppDynamics
Backed by Cisco, Splunk AppDynamics blends full-stack observability with AIOps smarts, so you can connect performance issues directly to business impact. From app response times to customer journeys to AI model performance, AppDynamics brings all your signals under one roof. And with its business lens, it’s easier to spot what needs attention.
Pros
Maps app performance directly to business KPIs for clearer impact analysis
Monitors AI and LLM-based applications (yes, even your GenAI stack)
Tracks user journeys to spot friction points across the app experience
Provides full-stack observability, not just apps, but infrastructure too
Offers dynamic baselining that adjusts to shifting traffic and usage patterns automatically
Cons
Works best within the Cisco ecosystem — can feel a bit limiting outside it
Initial setup and navigation may require a learning curve for some teams
BigPanda
BigPanda is a rapid incident detection and automation platform. Its smarter alert management feature auto-correlates alerts and adds rich context to help teams investigate faster. Powered by its AI engine BiggyAI, BigPanda doesn’t just show you what’s happening. It gives you the context to fix it fast. It acts like the bridge between your monitoring tools and your ops team, built for speed and scale.
Pros
Offers customizable summaries that give you more control over incident visibility
Provides high situational awareness that helps teams prioritize what matters
Enhances business impact visualization to show how incidents affect customers and revenue
Cons
Support response time can be hit or miss
Filtering options aren’t as flexible as some teams may need
A heavily code-focused setup might not suit all user levels
PagerDuty
If real-time incident response is a top priority for your team, PagerDuty is built to deliver. It’s an AIOps-powered platform designed to help IT and DevOps teams catch, assess, and resolve critical issues before they become major disruptions. Whether it's alert escalation, on-call management, or streamlined collaboration, PagerDuty brings clarity and speed to chaos, so you can stay focused on uptime, not firefighting.
Pros
Offers auto-escalation that keeps incidents moving
Enables seamless integration with a wide range of DevOps and monitoring tools
Boasts a clean, intuitive interface that doesn’t require a steep learning curve
Cons
Multilingual support is limited
Reporting and analytics aren’t as deep as some competitors
Setting up event workflows can be tricky at first
Dynatrace
If you're managing a sprawling, modern cloud environment and want complete visibility with AI-driven precision, Dynatrace is a serious contender. It’s an all-in-one observability platform built for enterprises that need more than just dashboards; it's ideal for those who need answers, fast. At the heart of it is Davis AI, Dynatrace’s powerhouse engine that connects the dots, finds root causes, and even fixes problems before your team gets involved.
Pros
Pinpoints root cause analysis that cuts through layers of complexity
Auto-discovers applications and maps dependencies, no manual setup required
Enables proactive issue detection to prevent downtime before it hits users
Cons
The pricing model is complex and can be hard to navigate
There’s a learning curve, especially for teams new to AIOps or large feature sets
Moogsoft
When your ops team is overwhelmed by alerts and constant firefighting, Moogsoft brings calm to the storm. This AIOps platform uses machine learning to filter noise, pinpoint root causes, and help teams resolve incidents faster, together. It’s especially handy for complex environments where traditional monitoring tools fall short and where cross-team collaboration is key to staying ahead.
Pros
Boasts adaptive thresholds and alert deduplication to reduce notification overload
Offers machine learning that evolves with your environment to catch emerging issues
Enables advanced correlation and classification to simplify incident triage and management
Extends strong situational awareness features that provide context around incidents
Cons
Documentation is limited, which can slow down onboarding
Heavy reliance on open-source resources for support
LogicMonitor
LogicMonitor is built for teams that need to monitor everything, on-prem, cloud, containers, and beyond. It’s a full-stack infrastructure monitoring platform that brings real-time visibility and AI-driven automation to even the most complex IT environments.
With its AI assistant Edwin AI and a conversational GenAI interface, LogicMonitor helps teams detect problems faster, streamline workflows, and manage it all from one powerful dashboard.
Pros
Spots anomalies and triggers rapid response actions with Edwin AI
Enables unified monitoring across networks, servers, apps, and multi-cloud services
Offers a conversational GenAI interface that makes navigation feel natural and efficient
Automates entire workflows, from alerting to resolution
Cons
Doesn’t offer deep application performance monitoring (APM)
Some reporting tasks lack automation out of the box
Splunk IT Service Intelligence (ITSI)
For teams overseeing complex digital environments, Splunk ITSI brings clarity and control. It offers a real-time, unified view of systems and services, helping teams understand not just where issues occur, but how they affect the business.
Pros
Offers intuitive, service-based dashboards that make it easier to spot issues and track what matters
Provides support for hybrid and multi-cloud environments, plus synthetic monitoring that enables teams to stay ahead of performance dips
Health scores and KPIs offer a quick snapshot of system performance and service status
Cons
Setting up integrations and tuning data sources can take time, especially in larger environments
Without fine-tuning, alerts can be noisy and distract from real issues
IBM Watson AIOps
For enterprise teams juggling complex systems, IBM Cloud Pak for AIOps offers a way to bring everything into focus. Built for scale, it connects tools, data, and teams, turning scattered signals into a clear picture of your IT health.
Pros
Gives full visibility across apps, infrastructure, and networks in one place
Builds real-time maps that show how systems connect and where issues could spread
Makes adoption easier with a low-code platform designed for speed and flexibility
Cons
Setup can be technically involved, especially in highly customized environments
Pricing may be a hurdle for mid-sized teams or those just starting their automation journey
ServiceNow ITOM
For teams managing hybrid or cloud-first infrastructures, ServiceNow ITOM acts as a central command center, bringing together visibility, automation, and intelligence to keep operations running smoothly. With Now Assist, its built-in generative AI engine, teams can analyze alerts, correlate events, and automate resolutions, reducing manual effort and accelerating incident response.
Pros
Creates a single source of truth for all IT operations
Offers built-in firewall auditing and compliance reporting
Speeds up cloud adoption and streamlines performance tracking
Cons
Requires technical expertise to fully implement and maintain
Discovery tools may miss components in more diverse or legacy environments; also, some third-party integrations could be more seamless
New Relic
New Relic is like a mission dashboard for engineering teams, offering deep, real-time visibility into your apps, infrastructure, and user experience. With GenAI capabilities and a powerful query engine, it helps you move from “what went wrong?” to “let’s fix this fast.”
From startups to large SaaS platforms, it’s built for teams that want data-backed decisions and smarter incident handling at speed and scale.
Pros
Defines custom Red-Amber-Green (RAG) statuses with historical views for clear performance tracking
Offers GenAI-driven recommendations that help speed up root cause analysis and scale smoothly across complex, high-volume environments
Supports forecasting in NRQL queries to spot trends before they become incidents
Cons
Offers limited network-level observability
Lacks out-of-the-box support for Azure Web Apps
ScienceLogic SL1
For IT teams managing large, distributed environments, ScienceLogic SL1 brings together visibility, automation, and proactive insights across hybrid and on-premises setups. The 2025 update (v12.3.3), DoDIN-certified for enhanced security, adds native Python 3.11 support and unlocks Skylar AI-powered analytics and anomaly detection.
Pros
Adapts easily to complex environments with deep customization options
Excels in network data collection, analysis, and monitoring
Automates detection and resolution to speed up incident handling
Tracks configuration changes to reduce risk and prevent surprises
Cons
Offers limited documentation, which can slow down onboarding
Requires time and expertise to fully unlock its more advanced features
Zluri
For teams juggling dozens of cloud apps, Zluri shines a light on every corner of your SaaS ecosystem, discovering even unsanctioned and AI-powered tools, while automating governance and cost controls.
Pros
Uncovers every SaaS app in use, including shadow IT and rogue AI tools
Automates onboarding, approvals, and access changes across the employee lifecycle
Tracks usage and spend to help you optimize your SaaS budget
Integrates smoothly with major SSO providers and leading SaaS platforms
Cons
Offers fewer native integrations compared to larger SaaS management or AIOps providers
Fabrix.ai
For IT teams navigating complex, hybrid environments, Fabrix.ai stands out with its Robotic Data Automation Fabric (RDAF) — a unified “data mesh” that automatically pulls together logs, metrics, and events into a single pane of glass, so you get context-rich alerts and actionable insights without stitching multiple tools together.
Pros
Offers a low-code interface for faster setup and customization
Provides ready-to-use dashboards and reporting to get insights quickly
Maps services and dependencies in detail so you always know how systems connect
Cons
The interface and overall usability could be smoother in some areas
Pricing
This breakdown highlights the varied pricing models for different tools, including per-host or per-agent charges, as well as custom or contact-based pricing for some tools.
AIOPs tool | Pricing |
Freshservice | Starter: $19/agent/month billed annually Growth: $49/agent/month billed annually Pro: $99/agent/month billed annually Enterprise: Custom pricing available |
Datadog | Free: Up to five hosts Pro: Starts at $15/month/host Enterprise: Starts at $23/month/host DevSecOps Pro: Starts at $22/month/host DevSecOps Enterprise: Starts at $34/month/host |
AppDynamics | Infrastructure monitoring edition: $6/CPU core/month billed annually Premium edition: $33/CPU core/month billed annually Enterprise edition: $50/CPU core/month billed annually |
BigPanda | Contact BigPanda for pricing |
PagerDuty | Starts at $699/month, billed annually |
Dynatrace | Full-stack monitoring: $0.08/hour/8 GiB host Infrastructure monitoring: $0.04/hour Kubernetes Platform monitoring: $0.002/hour Application security: $0.018/hour/8 GiB host Real user monitoring: $0.00225/session Synthetic monitoring: $0.001/synthetic request Ingest and process: $0.20/GiB Retain with included queries: $0.0007/GiB-day |
Moogsoft | Contact Moogsoft for pricing |
LogicMonitor | Infrastructure monitoring: $22/resource/month Cloud IaaS monitoring: $22/resource/month Wireless access points: $4/resource/month Cloud PaaS and container monitoring: $3/resource/month Log intelligence: Starts at $2.5/GB/month EdwinAI: Contact LogicMonitor for pricing |
Splunk ITSI | Contact Splunk for pricing |
IBM Cloud Pak AIOps | Contact IBM through their IBM Cloud Pak for AIOps webpage for pricing |
ServiceNow ITOM | Contact ServiceNow to get a custom quote |
New Relic | Free: 100/GB/month Contact New Relic to get custom pricing based on usability (Standard, Pro, and Enterprise) |
ScienceLogic SL1 | Standard: From $5/device/month Advanced: From $6/device/month Contact ScienceLogic for device group pricing |
Zluri | Contact Zluri for pricing |
Fabrix.ai | Contact Fabrix.ai for pricing |
How to choose the right AIOps tool for your organization
You’ve narrowed your choices. Now you're evaluating AIOps platforms to find the best fit for your IT operations. But which features matter most, and which are just surface-level selling points?
Use this checklist to evaluate with clarity:
Fast time-to-value
Select a platform that offers quick implementation and minimal setup. Solutions like Freshservice stand out with low-code onboarding and native connectivity with popular monitoring and observability tools. This helps you resolve real issues without spending weeks on setup configurations.
Explainable AI
Does the platform provide insight into why the AI flagged an alert? Top AIOps platforms offer complete transparency on how they analyze data, detect patterns, and reach specific conclusions.
Smart noise reduction
While each AIOps software promises alert noise reduction, the effectiveness of this feature varies. It’s recommended to go with platforms that offer adaptive suppression and intelligent alert grouping, especially the ones that are trained on datasets from companies similar to yours in size and complexity.
User-friendly interface
Your AIOps platform should be easy to use for everyone in your company. So, look for a modern, intuitive interface with clearly defined workflows for triaging and resolving incidents.
Built-in collaboration capabilities
Time is a useful resource when it comes to handling incidents. Your team must be able to coordinate responses without switching between systems. Platforms like Freshservice make collaboration faster by integrating natively with communication tools such as Slack, Teams, etc.
Forrester Wave™: Enterprise Service Management Platforms, Q4 2025
Freshworks named a Strong Performer, recognized for its unified service management and AI-augmented ITSM solution.
View Report

Total cost of ownership
Think about what it’ll cost to deploy, integrate, and maintain over time beyond just the license fee. A platform that’s “cheap” upfront might cost more in the long run. However, one that delivers value early and continues to scale with your needs is worth the investment.
Long story short, choose an AIOps tool that works with your stack, is easy for your team and takes work off your platform. A solution like Freshservice, powered by Freddy AI, helps your IT operations team resolve incidents faster and focus on what really matters.
Matching AIOps tools to your IT maturity
Not every AIOps platform fits every team, and that’s totally okay. The right tool depends on where you are in your IT journey and what you’re aiming for. Here’s how to find your match:
Organizational size and complexity: Choose tools that align with the scale of your operations. If you have a small team, opt for lightweight tools that are quick to deploy and easy to manage. If you are running a large enterprise, go for feature-rich platforms that can handle complex workflows and scale with your infrastructure.
Infrastructure diversity: Look for tools that support your environment — on-prem, cloud, hybrid, or multi-cloud — with native connectors and integration breadth.
Operational requirements: Prioritize specific capabilities based on your IT use cases, like capacity forecasting or predictive incident management.
Team skill sets and staffing: Consider the learning curve and automation flexibility to match your team’s expertise. If you have a lean IT team with limited AI experience, work with platforms that need low-code automation and offer intuitive dashboards. If you have data scientists on board, explore those that offer advanced customization.
Strategic alignment: Select platforms that support goals unique to your business, whether that’s reducing MTTR or improving service reliability.
Discover how AI helps IT do more with less: faster resolutions, smarter ops, better experiences
Key features to look for in an AIOps tool
Choosing the right AIOps platform goes beyond flashy dashboards. To truly support your IT operations, here are the core features that matter most:
Real-time analytics: The ability to process and analyze data as it’s generated is critical. A good AIOps tool offers instant insights into system health, performance issues, and anomalies so your team can act before users even notice.
Noise reduction and root cause analysis: Effective tools cut through alert fatigue by correlating signals and identifying what really needs attention. Built-in RCA (Root Cause Analysis) helps pinpoint the origin of issues faster, reducing mean time to resolution (MTTR).
Automated remediation: Beyond just identifying problems, top AIOps platforms can trigger automated workflows to resolve common incidents without human intervention, saving time and reducing errors.
Integration capabilities: Your AIOps tool should seamlessly integrate with your existing stack; monitoring systems, ITSM platforms, cloud services, and more. Native connectors and API support make it easier to unify operations.
Scalability and ease of deployment: Whether you're a mid-size team or a global enterprise, the platform should scale with you. Look for tools that are easy to deploy, configure, and maintain, even as your infrastructure grows.
Implementing AIOps tools: Best practices for success
Rolling out an AIOps platform requires setting your team and infrastructure up for long-term success. Here’s how to do it right:
Prepare your IT environment: Start by auditing your existing systems, tools, and data flows. AIOps relies on clean, connected data, so it’s important to ensure your monitoring, logging, and infrastructure layers are ready.
Align stakeholders and define goals: Get buy-in from leadership, IT, and operations teams early. Clearly define what success looks like, whether it’s reducing incident response time, automating ticket triage, or improving service reliability.
Focus on data integration and normalization: AIOps platforms thrive on consistent, high-quality data. Integrate logs, metrics, events, and other sources into a unified format to fuel better insights and automation.
Start with a pilot: Test the tool in a limited, controlled environment. Use the pilot to fine-tune thresholds, validate workflows, and measure early impact before scaling across your organization.
Commit to continuous monitoring and optimization: AIOps isn't set-and-forget. Keep refining the models, adjusting automations, and analyzing performance data to ensure the tool evolves with your infrastructure.

Train your teams: Equip your IT staff with the knowledge to interpret AI-driven insights and manage automation workflows. A well-trained team is key to getting full value from your AIOps investment.
Challenges and limitations of AIOps tools
While AIOps tools bring speed and intelligence to IT operations, the journey to full value isn’t without roadblocks. Here are some common challenges to be aware of:
Data silos and integration issues: AIOps platforms rely on unified data streams, but many organizations still operate in silos. Integrating data from different systems and tools can be time-consuming and may require custom connectors.
Complexity of deployment: Implementing AIOps isn’t always plug-and-play. From setting up data pipelines to configuring automation workflows, deployment can get complex, especially in large, hybrid environments.
Dependency on data quality: The accuracy of insights depends heavily on the quality of data fed into the system. Incomplete, noisy, or poorly labeled data can lead to false positives, or missed incidents altogether.
Managing expectations vs. reality: Teams need to understand that AI will enhance operations over time, not replace humans overnight. Setting realistic goals is key to long-term adoption.
Why Freshservice leads in AIOps innovation
The stakes are high when it comes to IT operations, especially when every delay or overlooked issue can cause significant downtime, hurt team productivity, and impact the bottom line. But that doesn’t have to be the reality. With the right AIOps platform, your team can stop reacting to problems and start staying ahead of them.
If you ask us, we’d recommend Freshservice AIOps, a powerful solution that’s already transforming how teams work, including at Texas A&M's transportation team, where they cleared a three-month ticket backlog in just 15 minutes after implementing Freshservice. The platform offers intelligent alert routing to make sure your team only gets the most important notifications, low-code automation to reduce manual work, and Freddy AI to provide real-time recommendations that empower your team to solve problems faster.
Freshservice AIOps also helps teams stay proactive by monitoring service health and using anomaly detection to spot issues before they become full-blown problems. And with clear, transparent pricing, you’ll have access to powerful tools without worrying about hidden fees or unnecessary add-ons.
Ready to transform how your team handles IT? Try Freshservice AIOps free for 14 days and experience what thousands of teams are already discovering — fewer surprises, faster resolutions, and a smarter, more efficient way to work.
From asset intelligence to incident prevention, discover practical AI use cases powering next-gen ITSM
Frequently asked questions
What is the difference between AIOps and traditional IT monitoring?
Traditional monitoring is rule-based — it watches for specific thresholds and alerts you when something crosses the line. AIOps goes several steps further. It uses machine learning to spot patterns, predict issues before they happen, cut down on alert noise and even suggest (or automate) fixes. It’s the difference between reacting to problems and staying ahead of them.
How long does it typically take to implement an AIOps solution?
It depends on how complex your IT environment is and which platform you choose. For most organizations, AIOps implementation takes anywhere from a few weeks to a few months. However, tools with pre-built integrations and low-code setups can speed things up significantly.
Can AIOps tools integrate with my existing IT infrastructure?
Absolutely. Most AIOps platforms are built to plug into what you already use — whether that’s ITSM systems, monitoring tools, cloud platforms, or on-prem servers. They usually support integration through APIs, native connectors, or preconfigured workflows.
Are AIOps tools replacing IT staff?
No, AIOps tools are designed to support IT teams, not replace them, by reducing manual tasks and helping them respond faster and more efficiently.
What are AIOps tools?
AIOps tools use AI and machine learning to automate IT operations. They analyze data from across systems to detect issues, predict outages, and speed up resolution.